The Requirement Spec is pretty thorough on what I've been trying to do, here I'll put some notes on current status & screenshots. (Hastily compiled, sorry, was concentrating on the code...).
In summary, I've got the system doing a good proportion of what I proposed, quite a few relatively minor bugs, and I did run into significant problems with integration into the Fusepool platform (have been using an ad hoc HTTP server and Fuseki SPARQL store during prototype dev, fewer moving parts :) I should be able to get these problems sorted out this week (end of June).
As ever, the code (on github) is the primary reference.
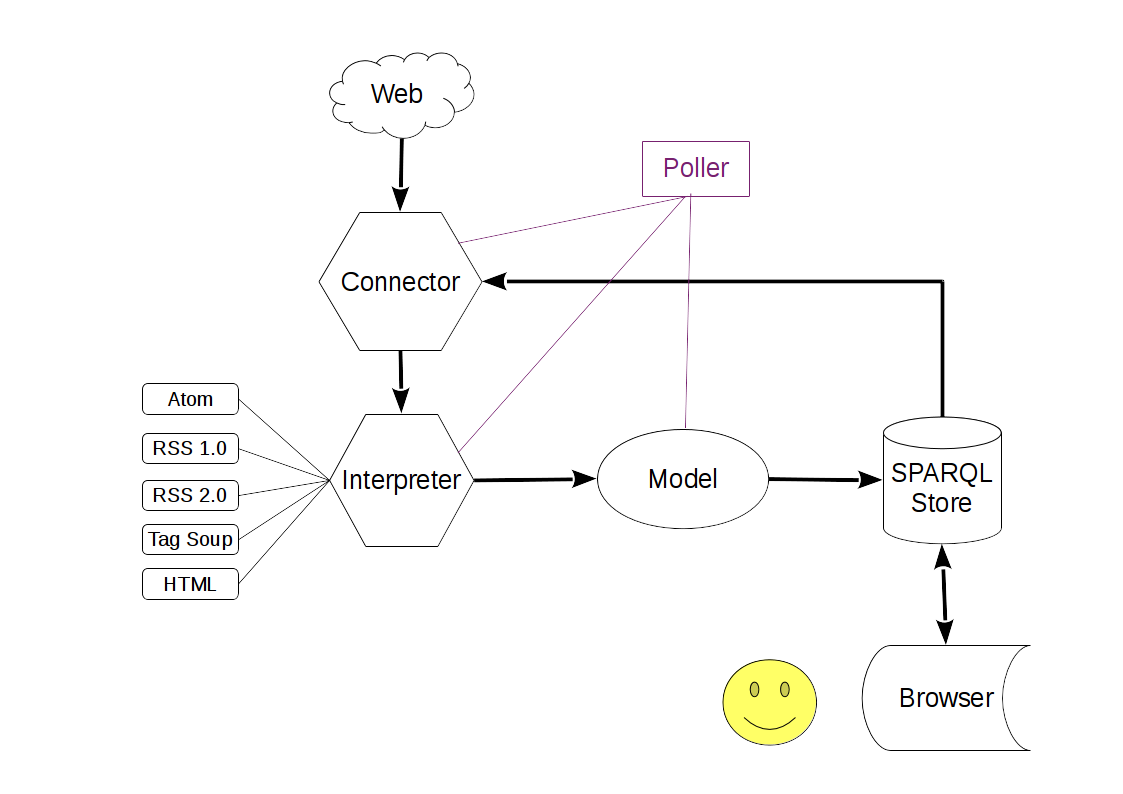
Here are a couple of excerpts. Note the system is multi-threaded, so things may not quite be in sequence. See below for diagrams of system data flow, model etc.
initialization phase - reads list of feed from store (or text file), sniffs each feed URL for status, feed format (feeds are often served with the wrong Content-Type) etc.
Starting from scratch (by config) the system will upload a plain text file of feeds URLs to the SPARQL store. Then, and on each subsequent restart, it'll load a list back from the SPARQL store, which will probably have been modified by other parts of the system.
Then for each feed URL it will do a HTTP GET and see if there's actually a feed available and attempt to identify the feed format. Four format species are supported: RSS 1.0, RSS 2.0, Atom and "Soup". Very often feeds contain elements not found in the specs or just messy markup, so a feed reader has to be fairly liberal in what it accepts. Where possible a SAX-based parser will be used, and the 3 primary implementations cover much of the material found in the wild. But if the feed contains broken XML, the system will fall back on the Soup parser (ironically it's a bit buggy at the time of writing) and try to interpret the material anyhow. If there are more fundamental problems (e.g. the link 404s or only provides HTML) the feed will be dropped from the list.
polling phase - the main feed loading loop, checks each feed, reads/interprets what it finds according to the appropriate parser into a common model, translates that into RDF and pushes the result into the SPARQL store. If problems are encountered with feed data here, the system takes note and will drop the feed from its list after a preset number of lives. The system supports Conditional GET (Etags & Last-Modified), which is available from many feed servers, so if the feed hasn't been updated since the last loop a full GET won't be done, saving bandwidth & processing.
A part of the processing of feeds is the extraction of any links in the (typically HTML) content of feed entries to enable discovery of further feeds. The prototype uses fairly crude regex-based extraction, after integration into the platform is should be possible to make this (and other content analysis/extraction) a lot more sophisticated.
I've made three main pages: Admin, Latest Entries and Links. They're implemented using client-side Javascript with jQuery/Ajax, the primary content provided by addressing the SPARQL store directly. It turned out to be relatively straightforward to formulate and apply the appropriate queries in-browser, with SPARQL results XML also parsed in-browser. (Though basically functional there are quite a few little unimplemented bits/minor bugs in these, the server-side data collection is mostly complete).
The Admin page will have basic controls, along with a list of current feeds and their status :

The Latest Entries page will be the main view. Entries are viewed most-recent first (nice-to-have: search-based lists, by-feed lists, quite a few other things are possible with little effort simply by modifying the SPARQL query in the Javascript source). To make it possible to skip to items of interest, I've used the jQuery UI accordion component, so an entry is displayed title-only until it's clicked, then unfolds to show the entry content. Here I've clicked on the 5th most recent item.

The Links page lists all the links known by the system, where they are feed URLs or ones extracted from entry content :

This largely follows what was in the requirements spec.
Data Flow overview:
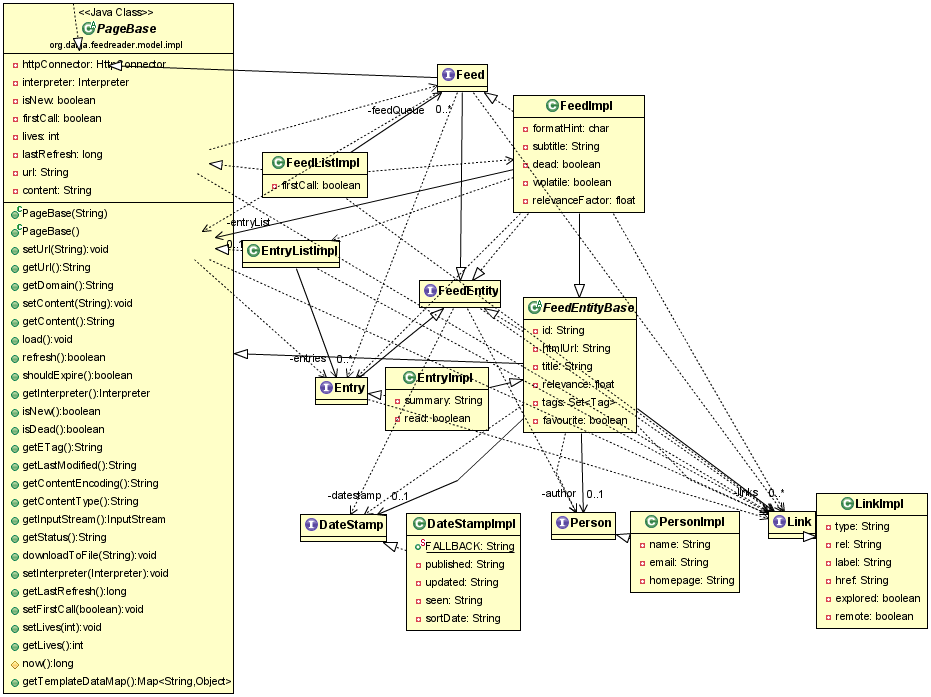
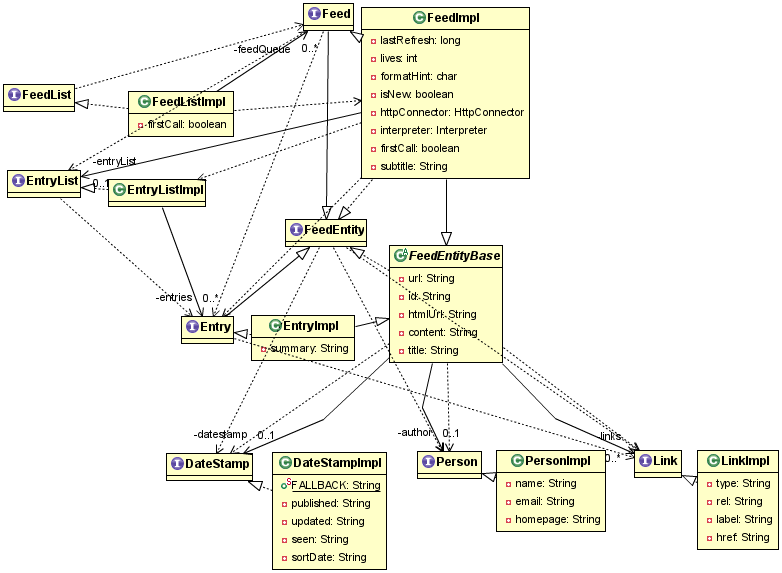
Primary data model (oops, I clearly didn't thin the UML on this one). Page loosely corresponds to a HTTP or RDF resource :